
作者:義大醫院 放射診斷科 李浩銘 醫師
相關文章:[快訊] 李浩銘醫師關於使用鋇劑與闌尾炎關聯性之健保資料庫研究,獲 American Journal of Medicine 刊登!

自參加 2014 年底的《健保資料庫工作坊》至今,孵了將近二年才生出第一篇成果,說來有些汗顏。小弟以這些淺薄經驗,提供給各位參考。其實這篇被接受的主題,已不記得是曾經做過的第幾個題目。
審視資源與自身強項
2015 年我申請院方的研究計畫,透過外包的統計公司進行研究設計與 data mining 後的分析,但一個案子的修改往往要來回十多次以上。外包的統計公司在效率低與配合意願不高的情況下,院方也不願意繼續和該公司簽約,我的研究也隨之胎死腹中。
儘管如此,這一年我還是有所收穫,知道怎麼快速、精準的寫 data mining protocol,讓統計分析團隊知道我們想找哪些變項?有哪些邏輯條件設定?
雖然透過《健保資料庫工作坊》,讓我一窺資料庫處理軟體 (MySQL) 之堂奧,但投入數十小時的學習後,深覺自己不是這方面的料。因此我轉而加強自己尋找臨床問題的能力,同時進行大量的背景閱讀。
至於統計與 program coding 部份,我還是找其他專業者協作。後來很慶幸找到高嘉鴻老師的團隊。(我知道很多人對他們的作法有爭議,但是他們也的確幫到我很多,開啟我很多的視野與想法。好壞與否非此處的重點,暫且不談。)
我的健保資料庫研究之作業流程
我的經驗是要找到有興趣、且健保資料庫能作的主題不難。但是魔鬼就在細節中,建議務必進行大量的背景閱讀,參考別人作過的類似研究,看看人家的 protocol 怎麼寫?抓什麼變項?有哪些 bias 或 confounding factors?可用什麼實驗設計方法排除或減低其影響?還有哪些沒回答的問題可以舉一反三探討?
一個主題,我大概會找 30 到 40 篇 reference 來看,background study 約耗時一周到一個月,視忙碌程度而異。能建立一個比較完整的 concept、有把握寫出 data mining protocol 後,下一步就是交給統計團隊跑初步結果,接著進行解讀。
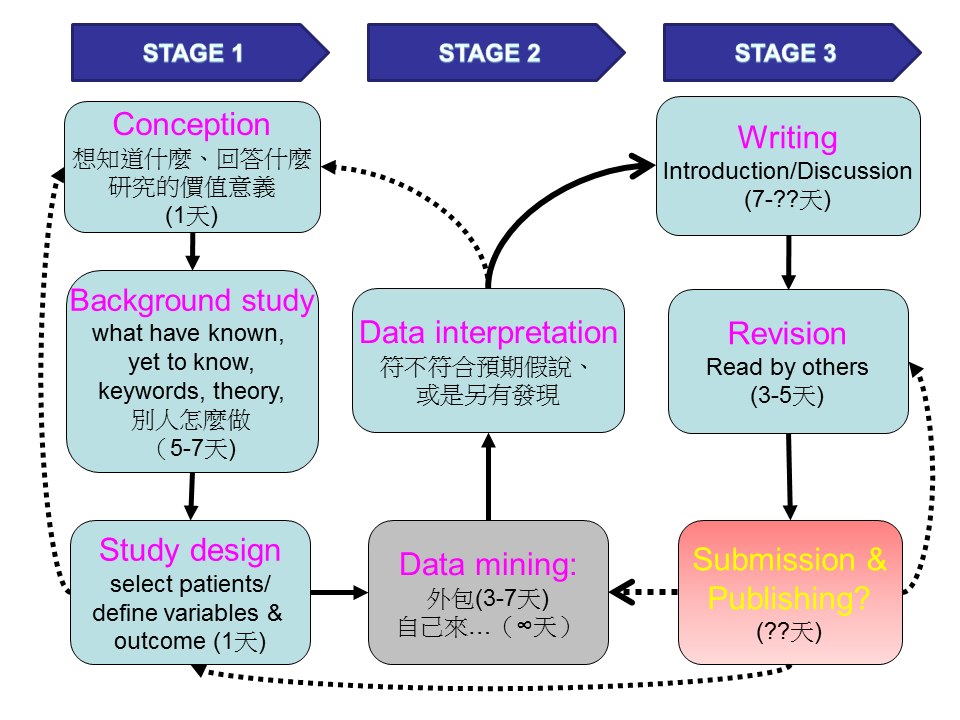
理想的 workflow 可以參考下圖,這圖來自我在科內會議分享 NHIRD 研究心得的簡報,本想多拉一些同伴合作,可惜沒有劉備般的魅力值 XD。簡報做的簡陋,野人獻曝、請勿見怪。
持續努力的動機與獲得的樂趣
就算分析出來的結果在解讀後不如預期,其實閱讀背景知識的過程也是一種樂趣,因為會發現很多離開學校後的知識缺口。譬如有一次我想查影響 AV shunt patency 的 risk factor,一路往下挖出 neointimal hyperplasia、atherosclerosis 和 venous thromboembolism 等機轉差異,便有種豁然開朗的喜悅(啊~原來我從前沒弄懂的東西,現在有這麼多進展了)。
還有很多的樂趣來自於「跨界」,有了解決問題的動機,便能有熱忱與其他科的醫師互動交流、虛心求教,為自己打開不同的窗。比如問心臟外科同學關於 AV shunt 的健保申報行為,還有病人 outcome 關注的點與放射科有何不同。跟腎臟科前輩也聊了多次,研究可行的 AV shunt failure 之定義。
有點可惜的是 2016 年因太太懷孕,環境上無法投資自己再多上些相關的課程,而在投稿中繞了些遠路。這篇被接受的論文,光投稿就耗時半年多,透過跟 reviewer 一次次的交手學習,終於在第 6 還是第 7 次投稿後獲得刊登。於期刊選擇和投稿後的審閱過程,我想我還沒有足夠好的策略應對,很多也是高主任幫忙提點,希望在往後能排出時間再次參與蔡校長的工作坊。
最新活動